12 Years of Gmail, Part 2: Bootstrapping
Posted on 08 November 2016 in Technology
This post is part of my series, 12 Years of Gmail, taking a look at the data Google has accumulated on me over the past 12 years of using various Google services and documenting the learning experience developing an open source Python project (Takeout Inspector) to analyze that data.
Jumping back in to Python has been just as fun as my first experiences with it. After brushing off some of the dust, I have managed to put together a (very) small package that does a couple of basic things with a Google Takeout Mail (mbox) file:
- Parses and standardizes the format of email addresses;
- Imports key messages data in to an sqlite database;
- Produces simple graphs of top recipients and senders.
Parsing Email Addresses
The mailbox Python module makes it very simple to get an mbox file in to Python and play around using the mailbox.Mailbox and email.Message classes. Here is an example using my mbox file:
0 1 2 3 4 5 6 7 8 9 | import mailbox email = mailbox.mbox('/path/to/email.mbox') # The number of emails in the mbox file. print len(email.keys()) 114407 # The "Delivered-To" header of the first email. print email[0].get('Delivered-To') my.address@hmail.com |
After using mailbox to establish a database and doing an initial import, I quickly noticed that many email addresses were either oddly formatted or differently formatted versions of the same address. Also, header fields with lists of address were not all the same format and often repeated addresses or had other issues. These inconsistencies made it difficult to aggregate information for specific addresses or otherwise organize SQL queries around them.
Here is an example header from the very first email in my mbox file (all of the actual email addresses are replaced with fake ones):
0 1 2 3 4 5 6 7 8 | John Smith <john@smith.com>, Joe Wilson <Joe.wilson@hmail.com>, <bobl1943@wahoo.com>, "Bill White" <bwhite@frontier.com>, Joe Johnson <jj@jandj.com>, Mike Proud <myfirstemail@wahoo.com>, Mom <Jill-Johnson@hmail.com>, Dad <bob-johnson@hmail.com>, "John Irving" <JOHN@johnirving.com>, Big bro <rob.m.johnson@hmail.com>, Jane Stevens <jane@stevens-inc.net>, Jane Stevens <jane@stevens-inc.net>, Michael Whitehead <mwh823@purdue.edu> |
There are a lot of problems to note here:
- Addresses are inconsistently separated by carriage returns.
- Most addresses are prefixed by a tab character.
- Some lines have one address, others have more than one.
- One email address does not have an associated name.
- Some names are surrounded in double quotes.
- One email address is repeated.
- Letter case is inconsistent.
None of this is particularly difficult to deal with in Python. Each address _is_ separated by a comma, for example, so creating a list from this header would be simple enough (but the comma is not always guaranteed!). I worked on parsing these fields and addresses manually a bit before finding the wonderful email.utils module.
The method email.utils.getaddresses can convert the above header to a list of name-email tuples without having to worry about the extraneous carriage returns, spaces or other formatting differences in the header:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | import email header = ['''John Smith <john@smith.com>, Joe Wilson <Joe.wilson@hmail.com>, <bobl1943@wahoo.com>, "Bill White" <bwhite@frontier.com>, Joe Johnson <jj@jandj.com>, Mike Proud <myfirstemail@wahoo.com>, Mom <Jill-Johnson@hmail.com>, Dad <bob-johnson@hmail.com>, "John Irving" <JOHN@johnirving.com>, Big bro <rob.m.johnson@hmail.com>, Jane Stevens <jane@stevens-inc.net>, Jane Stevens <jane@stevens-inc.net>, Michael Whitehead <mwh823@purdue.edu>'''] addresses = email.utils.getaddresses(header) print addresses [ ('John Smith', 'john@smith.com'), ('Joe Wilson', 'Joe.wilson@hmail.com'), ('', 'bobl1943@wahoo.com'), ('Bill White', 'bwhite@frontier.com'), ('Joe Johnson', 'jj@jandj.com'), ('Mike Proud', 'myfirstemail@wahoo.com'), ('Mom', 'Jill-Johnson@hmail.com'), ('Dad', 'bob-johnson@hmail.com'), ('John Irving', 'JOHN@johnirving.com'), ('Big bro', 'rob.m.johnson@hmail.com'), ('Jane Stevens', 'jane@stevens-inc.net'), ('Jane Stevens', 'jane@stevens-inc.net'), ('Michael Whitehead', 'mwh823@purdue.edu') ] |
Now some basic Python can clean things up a bit (using the addresses list created above):
0 1 2 3 4 5 6 | addresses = list(set(addresses)) for idx, address in enumerate(addresses): [local_part, domain] = address[1].split('@', 1) domain = domain.split('/', 1)[0].lower() local_part = local_part.replace('.', '').lower() address_formatted = local_part + '@' + domain addresses[idx] = [address[0], address_formatted] |
The above code block removes duplicates (Line 0), breaks each address in to its local and domain parts (Line 2), removes any resourcepart (Gmail stores chat data in the mbox file) (Line 3), converts all strings to lower case (Lines 3-4) and recombines the parts to update the entry in addresses (Lines 5-6).
Line 4 also removes any periods from the localpart. I initially did this because Gmail addresses ignore periods, however it now strikes me that this is likely not universally true! I will have to fix this in a forthcoming push of takeout inspector.
All together these operations create a list of unique tuples with standard relatively email address formatting:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 | print addresses [ ['Dad', 'bob-johnson@hmail.com'], ['Mike Proud', 'myfirstemail@wahoo.com'], ['Joe Johnson', 'jj@jandj.com'], ['Jane Stevens', 'jane@stevens-inc.net'], ['', 'bobl1943@wahoo.com'], ['Joe Wilson', 'joewilson@hmail.com'], ['Mom', 'jill-johnson@hmail.com'], ['Bill White', 'bwhite@frontier.com'], ['Big bro', 'robmjohnson@hmail.com'], ['John Irving', 'john@johnirving.com'], ['John Smith', 'john@smith.com'], ['Michael Whitehead', 'mwh823@purdue.edu'] ] |
Importing in to SQLite
Now that the To and CC headers can be parsed in to simple lists, the key data needs to be stored in a way that is easier (and quicker) to work with than Mailbox - enter SQLite. My experience is largely with MySQL so there was a bit of fumbling around getting this set up with Python's sqlite3 module. After I got the hang of it, I started poking through my entire mbox file (3.5GB) to figure out what information to import (for now).
I decided to start with three tables -
- messages to store some key information about all emails;
- headers to store raw headers for all emails;
- recipients to store one-row-per-address entries for any email address in the "To" or "CC" header.
The messages table includes the headers: From, To, Subject, Date, X-GM-THRID and X-Gmail-Labels. X-GM-THRID is a Gmail-specific numeric ID that relates messages in threads and X-Gmail-Labels stores a comma-separated list of labels for each email. Common labels include "Chat" for chat messages, "Sent" for sent emails, Important, Spam, etc.
The Date field is an interesting one to deal with because it needs to converted to a format that SQLite can use efficiently. SQLite relies on ISO 8601 while email Date headers use a format outlined in RFC 2822. Also, Gmail puts date information for its chat messages in a different header that is accessible using mailbox.mboxMessage.getfrom(). Once again using my mbox file as an example:
0 1 2 3 4 5 6 7 8 9 10 11 | import mailbox email = mailbox.mbox('/path/to/email.mbox') # A typical Date header. print email[0].get('Date') Mon, 5 Oct 2015 13:18:10 -0300 # A missing Date header for Gmail chats. print email[3].get('Date') None print email[3].get_from() xxx@xxx Mon Oct 05 00:37:04 +0000 2015 |
Both of these possibilies can be handled and converted to ISO 8601 format UTC dates using the email.utils and datetime Python modules. The following function assumes two parameters, the result of get('Date') and the result of get_from():
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | import email from datetime import datetime def get_message_date(get_date, get_from): if get_date: mail_date = get_date else: mail_date = get_from.strip()[-30:] datetime_tuple = email.utils.parsedate_tz(mail_date) if datetime_tuple: unix_time = email.utils.mktime_tz(datetime_tuple) mail_date_iso8601 = datetime.utcfromtimestamp(unix_time).isoformat(' ') else: mail_date_iso8601 = '' return mail_date_iso8601 |
- Lines 4-7 determine which of the two headers to use.
- Line 9 creates a tuple of the date including timezone information.
- Lines 10-14 attempt to convert the date tuples to ISO 8601 format.
Using the sane two example emails from my mbox file, the function above produces the following outputs:
0 1 2 3 | print get_message_date('Mon, 5 Oct 2015 13:18:10 -0300', None) 2015-10-05 16:18:10 print get_message_date(None, 'xxx@xxx Mon Oct 05 00:37:04 +0000 2015') 2015-10-05 00:37:04 |
Associating these formatted dates with the rows in messages allows for queries to be run with date/time parameters. For example, to see how many emails from my mbox were handled in December 2014, I can run:
0 1 2 | SELECT COUNT(`date`) FROM `messages` WHERE `date` >= '2014-12-01' AND `date` <= '2014-12-31'; 1086 |
If this data were not in a database, it would be necessary to loop through all the messages in my mbox to figure this out. Instead, this SQL query takes a measly 31ms.
The remaining tables (recipients and headers) don't deal with anything as "complex" (by comparision) as the messages.date column. Check out commit b6f5de9 on GitHub to see how these tables are populated as of this writing.
(Very) Basic Graphing using Plotly
I have not yet spent a lot of time considering the many Python graphing packages that are available. Overview of Python Visualization Tools is a quick review of some of the more popular packages that exist. After reading that article, I elected to give Plotly a try as it appeared to have the quickest path to interactive graphs (and it did prove to be quite fast). There really isn't much happening on this front yet. I only pushed out this bit of code to get a feel for pulling data from SQLite in to Plotly.
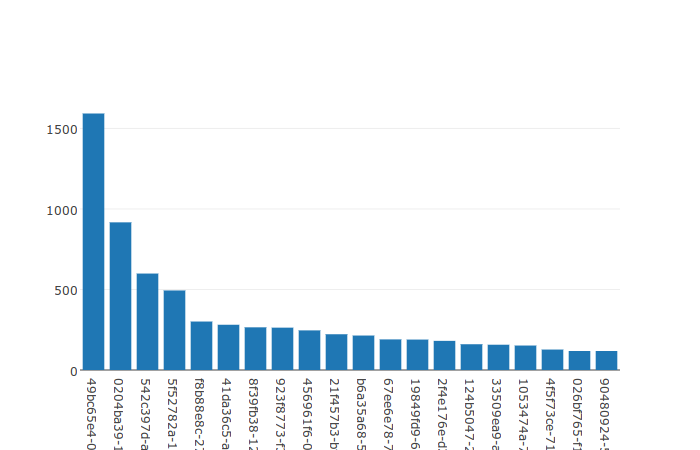
Top 20 Recipients
To produce a Top 20 Recipients bar graph with the default Plotly formatting, I can execute the following SQL from Python and massage the results a bit to create a graph in just a few lines of code:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | import plotly.offline as py import plotly.graph_objs as go import sqlite3 from collections import OrderedDict conn = sqlite3.connect('/path/to/email.db') c = self.conn.cursor() c.execute('''SELECT address, COUNT(r.message_key) AS message_count FROM recipients AS r LEFT JOIN messages AS m ON(m.message_key = r.message_key) WHERE m.gmail_labels LIKE '%Sent%' GROUP BY address ORDER BY message_count DESC LIMIT ?''', (20,)) addresses = OrderedDict() for row in c.fetchall(): addresses[row[0]] = row[1] py.plot([go.Bar( x=addresses.keys(), y=addresses.values()) ]) |
One thing that I discovered while working on this code: a typical Python dict is unordered. Luckily, there is a collections.OrderedDict object that respects the order of the SQL query results (Lines 16-18). With that data in a dict, all Plotly needs is the the X and Y lists (Lines 20-23) to produce a simple, interactive graph! And a good deal of Javascript, of course...
Note that the resulting graph uses anonymized email addresses. This is handled by the code, but not something I will be discussing quite yet as I want to look in to some other ways to do this. The method used for these graphs is available to view in commit b6f5de9.
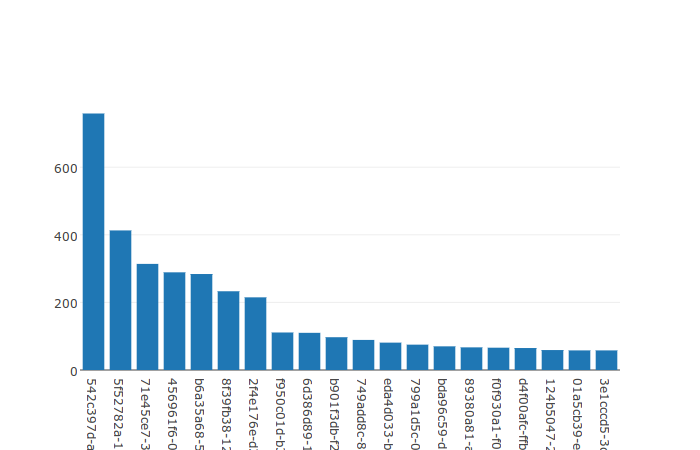
Top 20 Senders
Similarly, a Top 20 Senders bar graph is simple to create from the messages table using the same code as above and this SQL query:
0 1 2 3 4 5 6 | SELECT `from`, COUNT(message_key) AS message_count FROM messages WHERE gmail_labels NOT LIKE '%Sent%' AND gmail_labels NOT LIKE '%Chat%' GROUP BY `from` ORDER BY message_count DESC LIMIT 20 |